A slightly cryptic issue appeared on the esp32-tv project:
This is pretty interesting - SIMD (Single Instruction Multiple Data) can potentially really speed up decoding of JPEG files.
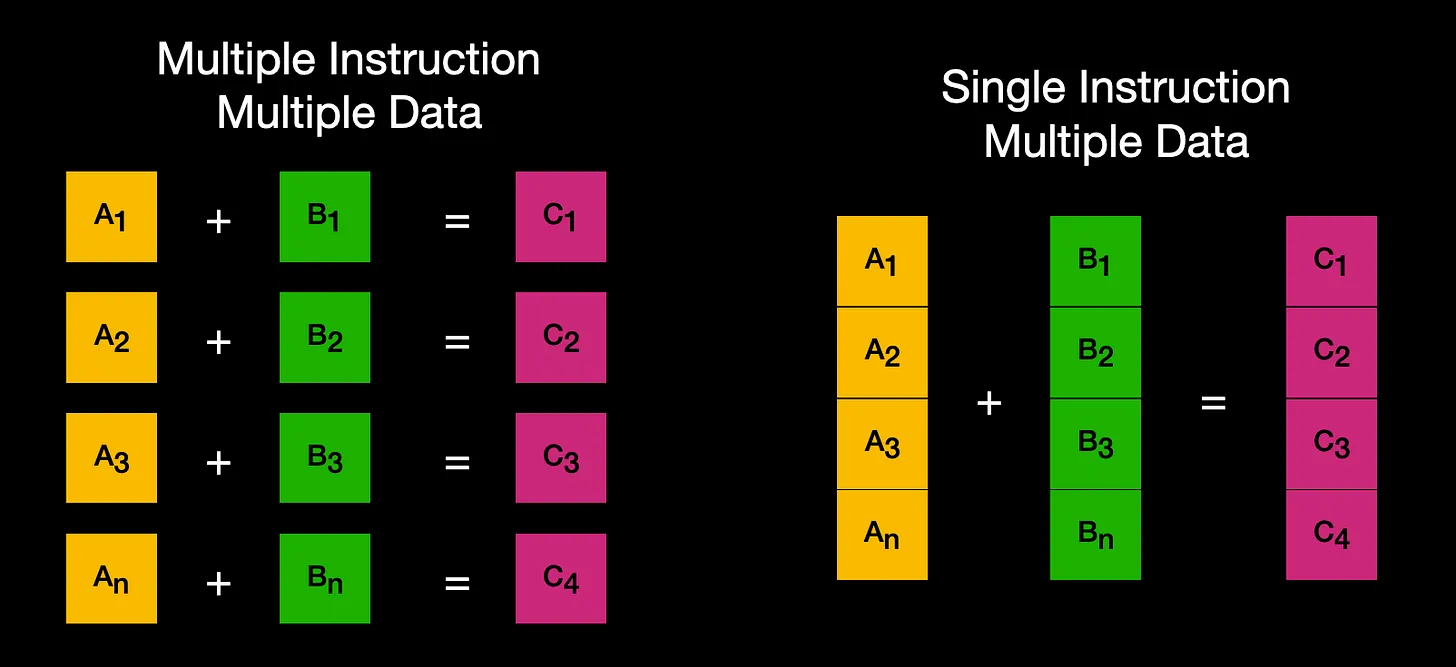
Normally when executing code you run an instruction that operates on a single piece of data, then you run the next instruction, and the next instruction etc.. we have Multiple Instructions operating on Multiple Data elements.
With SIMD instructions we have one Single Instruction that can then operate on Multiple Data elements.
This can give a significant performance boost.
So, just how much fast is the decoding library I was sent? It’s pretty damn fast - 20ms to decode my test image (272x233 pixels) on an ESP32-S3.
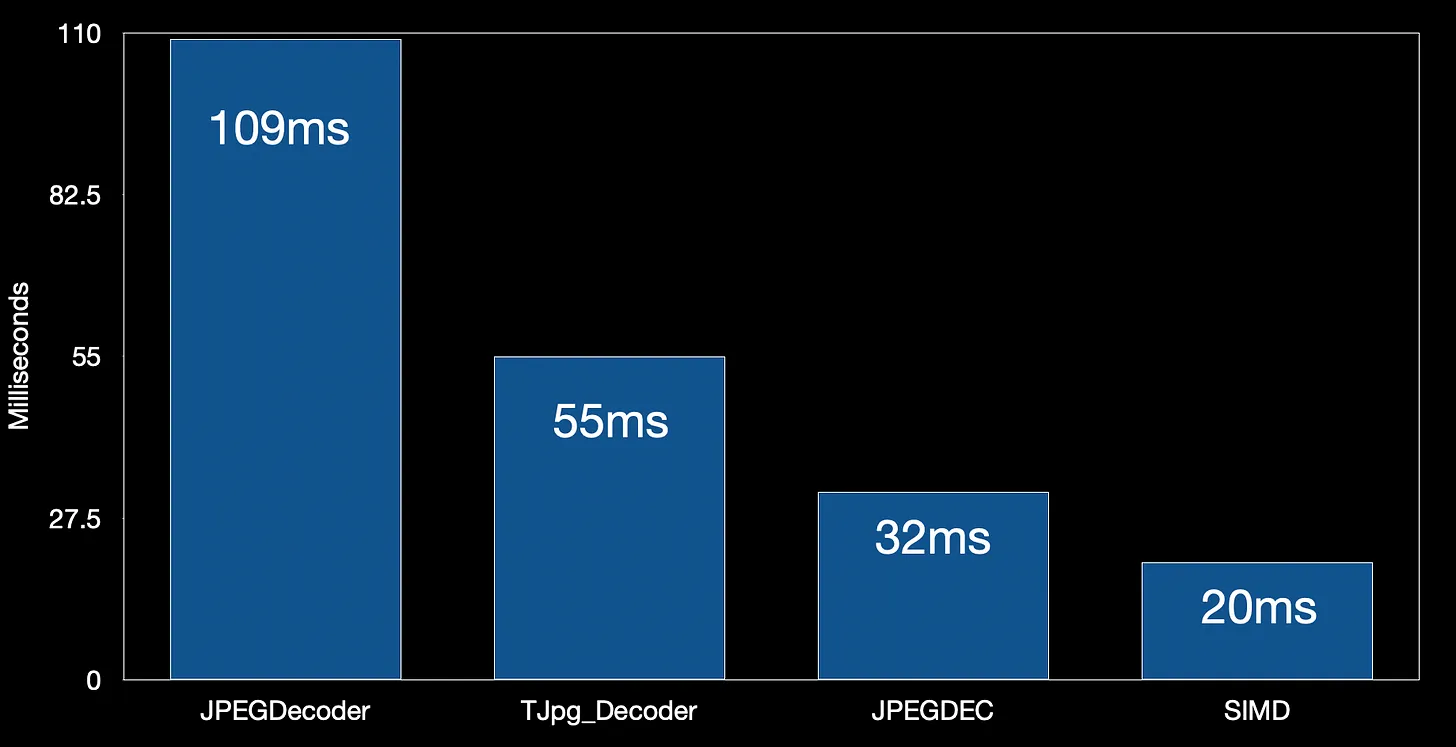
So that’s pretty amazing! But there’s something very interesting when we start to draw the images - and there’s no point decoding images if we don’t display them!
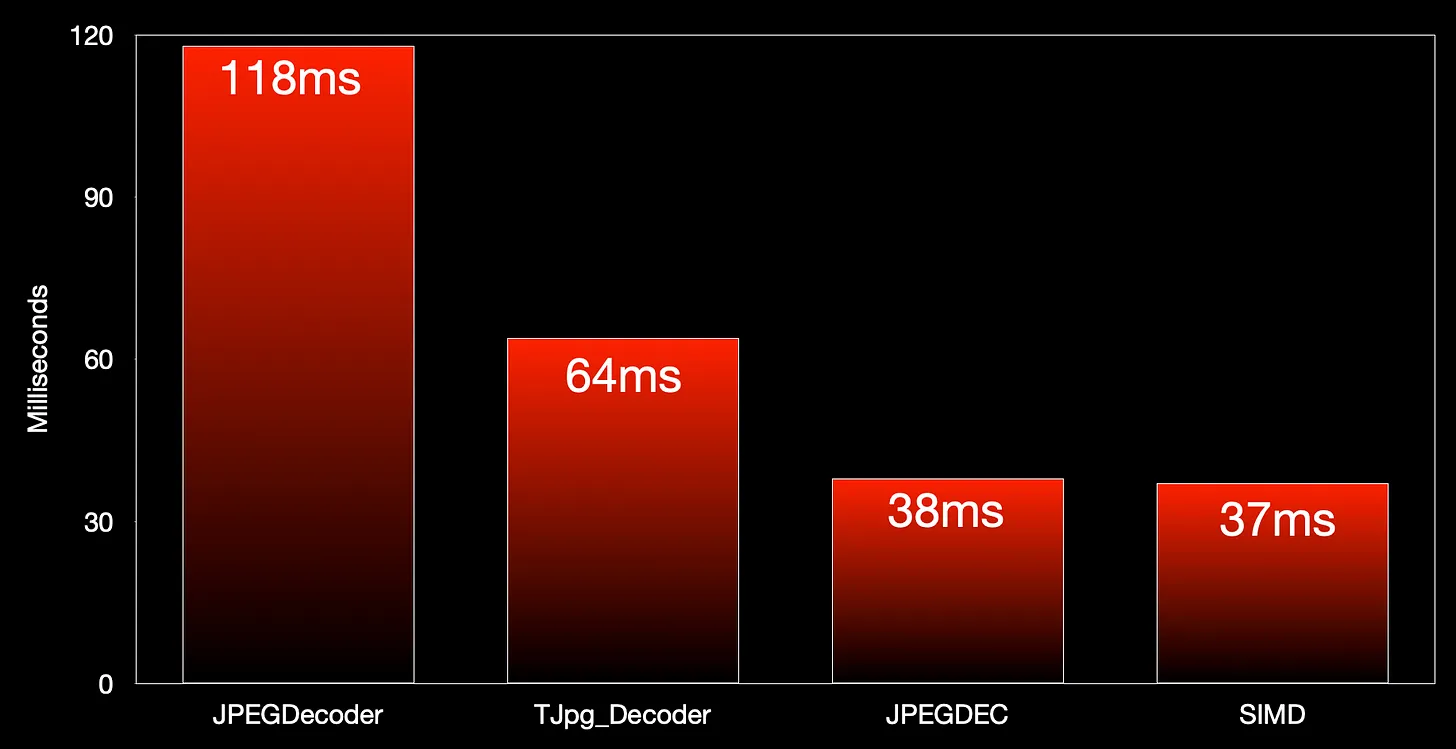
The extra time needed to draw the image is really high for our new library - in fact it now only performs as well as our existing JPEGDEC library.
This is kind of weird - we’re pushing exactly the same number of pixels to the display - why should the new library have such a big overhead when drawing?
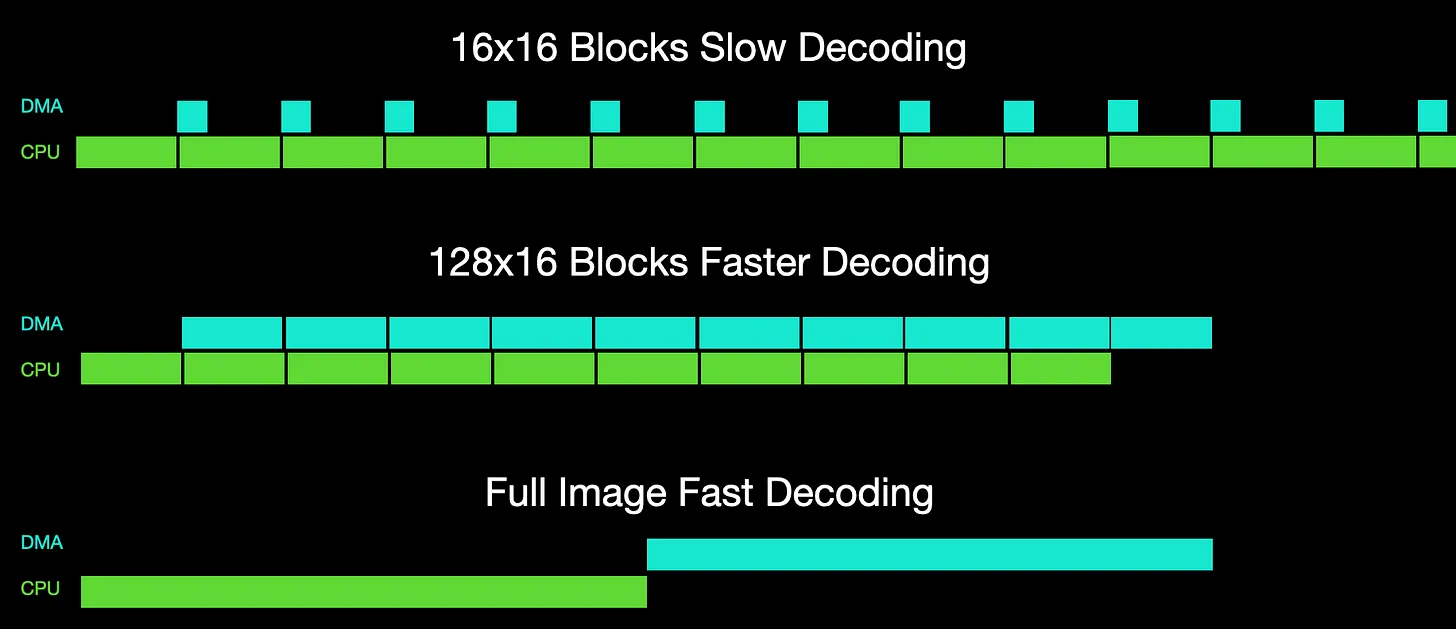
There’s actually a pretty simple explanation for this. We’re using DMA to draw pixels. With our existing libraries we decode the JPEG image one block of pixels at a time. With the JPEGDecoder and TJpg_Decoder libraries this is a block of 16x16 pixels. With the JPEGDEC library it’s 128x16 pixels - If you check out the video I’ve slowed down the drawing so you can see this.
This means that we can send a block of pixels off to the display using DMA, which then lets the CPU get on with decoding the next block of pixels - while the previous block is being sent to the display.
With the new fast library the image is decoded all in one go - this means that we don’t get any overlap. The CPU does its work, and then the DMA pushes all the pixels out at once.
Initially this might seem a little bit disappointing, but it’s actually not the end of the world - particularly for out TV project where we are streaming frames.
We can decode a frame using the CPU and kick off the DMA transfer to display the pixels. And then we can immediately kick off decoding the next frame. This overlapped decode/display process can give us a really fast frame rate.

I’ve done some very simple experiments and managed to get around 40 frames per second - which is pretty impressive!
You can watch the detailed video here: